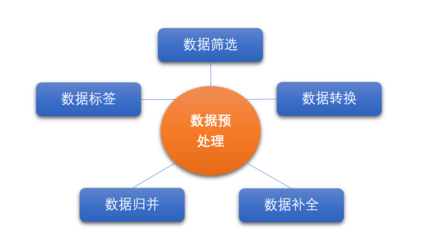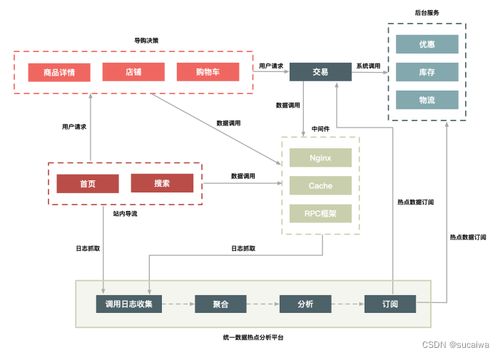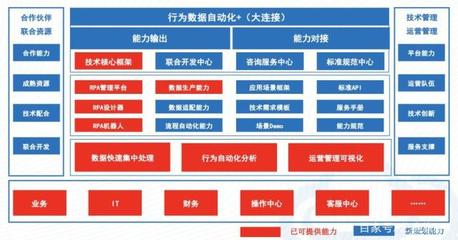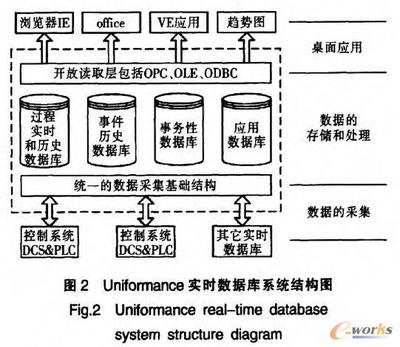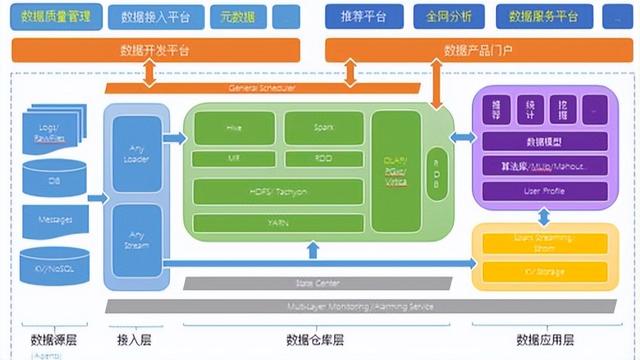
在數(shù)字化時(shí)代,數(shù)據(jù)已成為企業(yè)最寶貴的資產(chǎn)之一。構(gòu)建一個(gè)高效、可擴(kuò)展且穩(wěn)健的數(shù)據(jù)處理系統(tǒng),離不開精心設(shè)計(jì)的大數(shù)據(jù)架構(gòu)圖。這不僅是一個(gè)技術(shù)藍(lán)圖,更是連接數(shù)據(jù)源頭與業(yè)務(wù)價(jià)值的關(guān)鍵橋梁。本文旨在探討大數(shù)據(jù)架構(gòu)圖設(shè)計(jì)的核心要素,以及如何構(gòu)建一個(gè)高效的數(shù)據(jù)處理服務(wù)。
一、 大數(shù)據(jù)架構(gòu)圖的核心構(gòu)成
一個(gè)典型的大數(shù)據(jù)架構(gòu)圖通常遵循分層設(shè)計(jì)理念,以實(shí)現(xiàn)邏輯清晰、職責(zé)分離和靈活擴(kuò)展。其核心層次通常包括:
- 數(shù)據(jù)采集與接入層: 這是數(shù)據(jù)管道的起點(diǎn)。負(fù)責(zé)從各種異構(gòu)數(shù)據(jù)源(如業(yè)務(wù)數(shù)據(jù)庫、應(yīng)用程序日志、物聯(lián)網(wǎng)設(shè)備、第三方API等)實(shí)時(shí)或批量地采集數(shù)據(jù)。常見的工具有Apache Kafka(用于實(shí)時(shí)流)、Apache Flume、Sqoop以及云服務(wù)商提供的各種數(shù)據(jù)遷移工具。
- 數(shù)據(jù)存儲(chǔ)層: 根據(jù)數(shù)據(jù)的熱度、訪問模式和結(jié)構(gòu),選擇合適的存儲(chǔ)方案。這通常是一個(gè)混合存儲(chǔ)體系:
- 批處理數(shù)據(jù)湖: 使用如Hadoop HDFS或云對象存儲(chǔ)(如AWS S3,阿里云OSS)來低成本、高可靠地存儲(chǔ)原始數(shù)據(jù),支持任意格式,為后續(xù)探索性分析奠定基礎(chǔ)。
- 實(shí)時(shí)/交互式數(shù)據(jù)庫: 如Apache HBase、Cassandra,用于低延遲的隨機(jī)讀寫。
- 分析型數(shù)據(jù)倉庫: 如Apache Hive on Tez/Spark、云數(shù)據(jù)倉庫(如Snowflake,阿里云MaxCompute),用于對清洗后的數(shù)據(jù)進(jìn)行復(fù)雜的SQL查詢和分析。
- 數(shù)據(jù)處理與計(jì)算層: 這是架構(gòu)的“引擎”,負(fù)責(zé)將原始數(shù)據(jù)轉(zhuǎn)化為有價(jià)值的信息。它通常分為兩條并行的處理路徑:
- 批處理路徑: 處理海量歷史數(shù)據(jù),計(jì)算周期長(如小時(shí)、天)。核心引擎是Apache Spark(因其內(nèi)存計(jì)算和易用性已成為主流)或MapReduce。
- 流處理路徑: 處理無界數(shù)據(jù)流,實(shí)現(xiàn)亞秒級到秒級的低延遲分析。常用框架有Apache Flink(因其高吞吐、低延遲和精確一次語義而領(lǐng)先)、Apache Spark Streaming以及Kafka Streams。
- 數(shù)據(jù)服務(wù)與應(yīng)用層: 將處理好的數(shù)據(jù)以服務(wù)的形式暴露給下游應(yīng)用。這包括:
- OLAP分析服務(wù): 通過Presto、Druid、ClickHouse等提供高速多維分析。
- 數(shù)據(jù)API服務(wù): 通過RESTful API或GraphQL將數(shù)據(jù)提供給業(yè)務(wù)系統(tǒng)、數(shù)據(jù)產(chǎn)品(如推薦系統(tǒng)、風(fēng)控模型)和可視化報(bào)表。
- 數(shù)據(jù)治理與安全層(貫穿始終): 這不是一個(gè)獨(dú)立的物理層,而是橫跨所有層次的關(guān)鍵能力。它包括元數(shù)據(jù)管理(如Apache Atlas)、數(shù)據(jù)血緣追蹤、數(shù)據(jù)質(zhì)量管理、統(tǒng)一的安全認(rèn)證與權(quán)限控制(如Apache Ranger),確保數(shù)據(jù)的可靠性、可信度與合規(guī)性。
二、 構(gòu)建高效數(shù)據(jù)處理服務(wù)的關(guān)鍵原則
在設(shè)計(jì)架構(gòu)圖時(shí),應(yīng)遵循以下原則以確保數(shù)據(jù)處理服務(wù)的高效性:
- Lambda與Kappa架構(gòu)的抉擇與融合: 經(jīng)典的Lambda架構(gòu)同時(shí)維護(hù)批處理和流處理兩套邏輯,保證容錯(cuò)但存在代碼重復(fù)。Kappa架構(gòu)主張用一套流處理系統(tǒng)處理所有數(shù)據(jù),簡化了架構(gòu)。在實(shí)踐中,可根據(jù)業(yè)務(wù)場景融合兩者,例如用流處理處理實(shí)時(shí)需求,同時(shí)定期用批處理進(jìn)行數(shù)據(jù)重算和糾偏。
- 解耦與彈性擴(kuò)展: 各層次之間通過消息隊(duì)列(如Kafka)或?qū)ο蟠鎯?chǔ)解耦,允許各組件獨(dú)立擴(kuò)展,提高系統(tǒng)整體的彈性和容錯(cuò)能力。利用云原生的彈性伸縮能力可進(jìn)一步優(yōu)化成本與性能。
- “可觀察性”設(shè)計(jì): 從架構(gòu)設(shè)計(jì)之初就集成全面的監(jiān)控(Metrics)、日志(Logging)和追蹤(Tracing),實(shí)時(shí)掌握數(shù)據(jù)管道的健康狀態(tài)、處理延遲和數(shù)據(jù)質(zhì)量,便于快速定位和解決問題。
- 自動(dòng)化與DevOps: 將數(shù)據(jù)管道即代碼(Pipeline as Code),利用CI/CD工具實(shí)現(xiàn)數(shù)據(jù)處理作業(yè)的自動(dòng)化測試、部署和運(yùn)維,提升開發(fā)運(yùn)維效率與系統(tǒng)可靠性。
三、 架構(gòu)圖設(shè)計(jì)實(shí)踐:一個(gè)簡化的示例流程
以一個(gè)電商用戶行為分析場景為例,其簡化的大數(shù)據(jù)架構(gòu)流程可描述為:
- 用戶在前端的點(diǎn)擊、瀏覽、購買等日志,通過SDK實(shí)時(shí)發(fā)送到Apache Kafka(數(shù)據(jù)接入層)。
- 一個(gè)Apache Flink實(shí)時(shí)作業(yè)(流處理層)消費(fèi)Kafka中的數(shù)據(jù),進(jìn)行實(shí)時(shí)過濾、聚合(如實(shí)時(shí)熱門商品),并將結(jié)果寫入Apache Druid(數(shù)據(jù)服務(wù)層)用于實(shí)時(shí)大盤展示,同時(shí)將原始數(shù)據(jù)備份到云對象存儲(chǔ)S3(數(shù)據(jù)湖存儲(chǔ)層)。
- 每日凌晨,一個(gè)Apache Spark批處理作業(yè)(批處理層)從S3中讀取全天數(shù)據(jù),進(jìn)行更復(fù)雜的清洗、關(guān)聯(lián)(如連接用戶屬性表)和聚合,生成結(jié)構(gòu)化的業(yè)務(wù)寬表,并寫入云數(shù)據(jù)倉庫(如Snowflake,分析存儲(chǔ)層)。
- 業(yè)務(wù)分析師通過BI工具(如Tableau,應(yīng)用層)連接數(shù)據(jù)倉庫和Druid,進(jìn)行自助分析與報(bào)表制作。推薦系統(tǒng)通過數(shù)據(jù)API(數(shù)據(jù)服務(wù)層)調(diào)用處理后的用戶畫像和商品特征數(shù)據(jù)。
- 統(tǒng)一元數(shù)據(jù)與權(quán)限管理系統(tǒng)(治理層)監(jiān)控整個(gè)流程的數(shù)據(jù)血緣,并管理各層數(shù)據(jù)的訪問權(quán)限。
###
一張優(yōu)秀的大數(shù)據(jù)架構(gòu)圖,是技術(shù)選型、流程設(shè)計(jì)與業(yè)務(wù)目標(biāo)緊密結(jié)合的產(chǎn)物。它沒有一成不變的標(biāo)準(zhǔn)答案,但核心在于平衡實(shí)時(shí)性與準(zhǔn)確性、靈活性與成本、開發(fā)效率與系統(tǒng)穩(wěn)定性。隨著云原生、湖倉一體(Lakehouse)和流批一體(如Flink)等技術(shù)的發(fā)展,現(xiàn)代大數(shù)據(jù)架構(gòu)正朝著更簡化、更統(tǒng)一、更智能的方向演進(jìn)。設(shè)計(jì)者需要持續(xù)關(guān)注技術(shù)趨勢,并始終以解決實(shí)際業(yè)務(wù)問題、高效釋放數(shù)據(jù)價(jià)值為最終目標(biāo)來繪制和迭代這張至關(guān)重要的技術(shù)藍(lán)圖。